
论文学习+解读1--受优化算法启发的DNN网络设计
今天学习论文:【Optimization Algorithm Inspired Deep Neural Network Structure Design】
https://zhouchenlin.github.io/Publications/2018-ACML-Network.pdf自从听了ruoyu Sun的关于深度学习优化理论的暑期班后
Zootopia:名校随处可见的暑期班,你能学到什么?---Ruoyu Sun北大暑期班笔记对优化算法这个在DNN中的黑箱子,充满了好奇。今天学习的这篇论文来自北大团队Huan Li, Yibo Yang, Dongmin Chen 和Zhouchen Lin。
摘要开门见山提出现在DNN已经蓬勃发展,尤其像ResNet和DenseNet的提出引起了不小的轰动,但是随着如春笋般涌出的各种Net,每个Net往往都是实践表明效果很好,却没有一个统一的对于神经网络结构的设计框架。这篇论文基于的思想是:神经网络可以受优化算法启发来设计网络结构,并且更快的优化算法可以得到更好的网络设计。
观察:前向神经网络传播(假设每层线性变换一致)等价于利用梯度下降法优化某个目标函数
基于这个观察可以通过将现有的heavy ball或者是Nesterov加速算法来替代GD,从而得到更好的网络设计。ResNet和DenseNet都是其统一框架的特殊情形。
从优化算法的角度建立了unified framework,不仅为后续网络优化提供了理论思路,也为优化和DNN建立了更紧密的联系
【受压缩感知领域的启发】传统压缩感知一般常用的是解决这样一个优化问题(L1正则化问题)
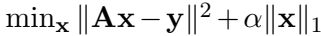
这个问题涉及到迭代中求解

这个步骤很费时、需要迭代很多步才能保证收敛(虽然也有大量的文献努力在提高此步骤的效率)。针对这个问题,以下文献(可能包含的不全)
G. Huang, Z. Liu, L. van der Maaten, and K. Weinberger. Densely connected convolutional
networks. In CVPR, 2017.
B. Xin, Y. Wang, W. Gao, B. Wang, and D. Wipf. Maximal sparsity with deep networks?
In NIPS, 2016
K. Kulkarni, S. Lohit, P. Turaga, R. Kerviche, and A. Ashok. Reconnet: Non-iterative
reconstruction of images from compressively sensed mmeasuremets. In CVPR, 2016
J. Zhang and B. Ghanem. ISTA-Net: Iterative shrinkage-thresholding algorithm inspired
deep network for image compressie sensing. In arxiv:1706.01929, 2017建立了基于神经网络的方法来解决压缩感知问题,核心思想是:给定深度,训练一个非线性的前向神经网络,在每一层,对输入做一个非线性变换
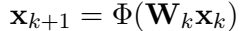
Wk是可以学习的,这样,相比传统压缩感知W是固定的,这样的方法更高效。
【个人觉得,以上方法也是NN和CS的一种联系,做CS的人通过NN的经典思想来改进CS优化迭代算法,这样的联系也能反过来影响DNN】
这篇论文不考虑最优权的部分。主要贡献在于
- 建立了优化算法和DNN之间的初步联系(论文作者一直强调初步,很谦虚也很严谨)
- 建立了一个基于优化算法的unified 框架,为DNN网络设计提供了理论思路
在神经网络中,前向传播一般表示为

这里 是例如ReLU和sigmoid的激活函数,因为这篇论文不考虑最优
,所以可以直接视为W。
而梯度下降算法中主要迭代为

【怎么建立(1)和(7)的联系?】

本质上就是找到了GD需要最优的目标函数F(x),这也是这个论文最重要的引理--建立了NN和GD的联系
针对不同的激活函数,论文中都有提供其对应目标函数

既然神经网络可以等价于利用GD来优化一个目标函数,那么尝试是否更快的算法,此文主要考虑了Heavy ball、Nesterov's加速算法以及近些年在优化领域很火的ADMM(交替方向乘子算法)能否对应更好的神经网络。
Heavy ball:
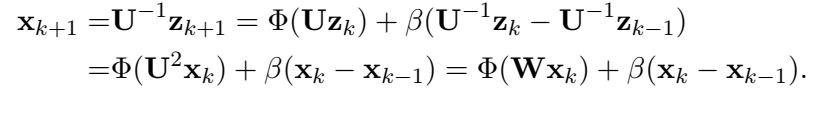
Nesterov's
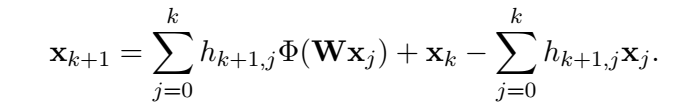
ADMM(ADMM是并行算法,所以是两个量同时算)
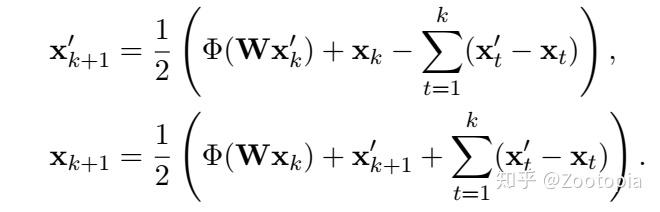
有了网络和算法之间的联系表达式,现在就是付诸于实践看,这样的网络效果如何
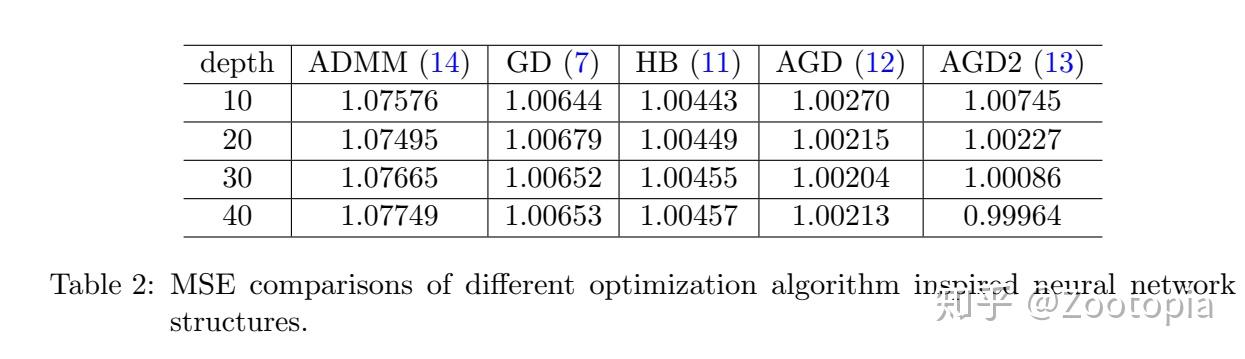
从表格中看到:
(1)Nesterov's的两个版本AGD和heavy ball都比GD效果更好,这也和他们比GD收敛速率更快的理论符合
(2)ADMM效果最差,这也和ADMM收敛并不比GD好的理论符合【前几年,关于ADMM的收敛分析曾经掀起很大的一波研究热潮】
(3)随着网络深度加深,大部分方法的MSE并不会随着继续减少,意味着基于GD,HB,AGD的深度网络较难训练,AGD2却仍然很有效(虽然AGD2和AGD理论是一致的)
放松 和W:考虑把
设置为池化、BN、卷积或者全连接的组合函数,这样,网络就可以覆盖CNN一类的网络
自适应调整参数:可以考虑把参数 等做自适应的调整、或者设置为0。例如
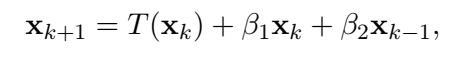
把 设为0,就是ResNet; 下面这个表格涵盖了几种常用方法


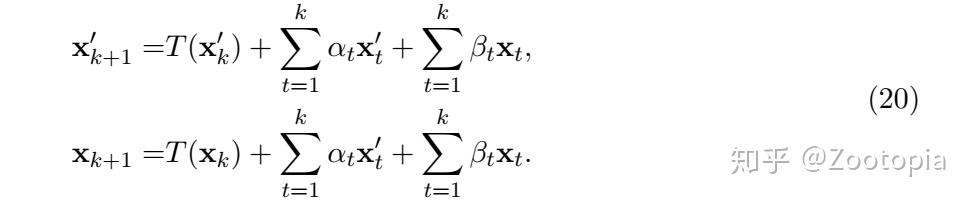
直接上数据结果:
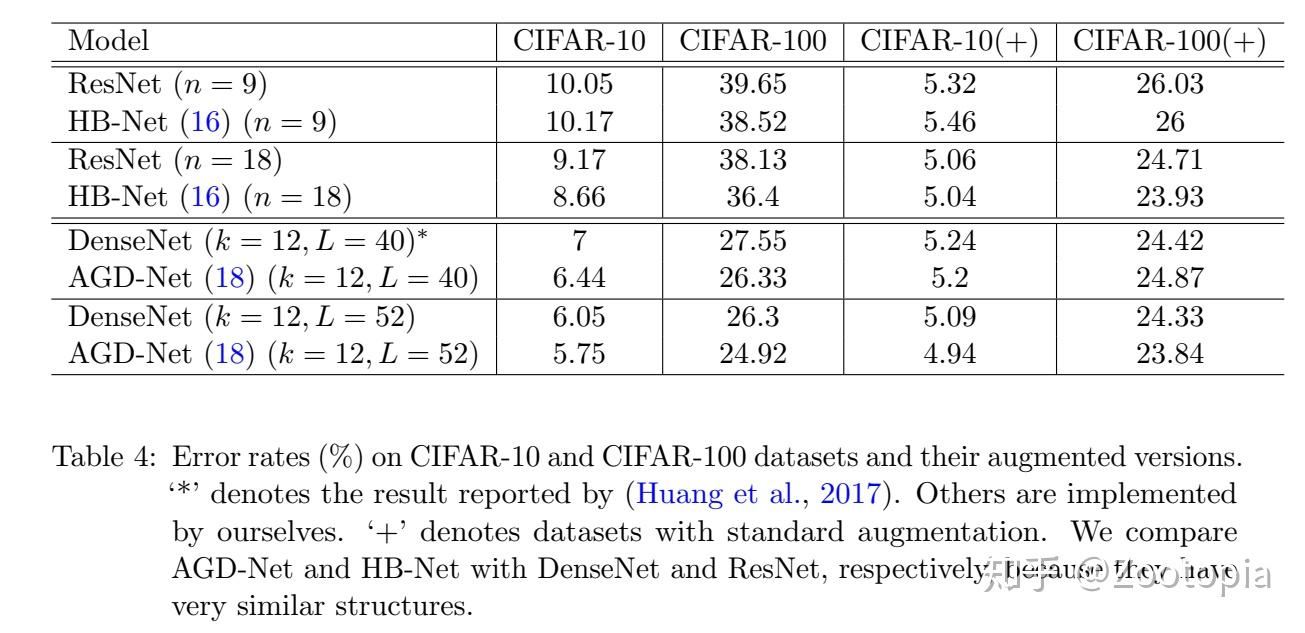
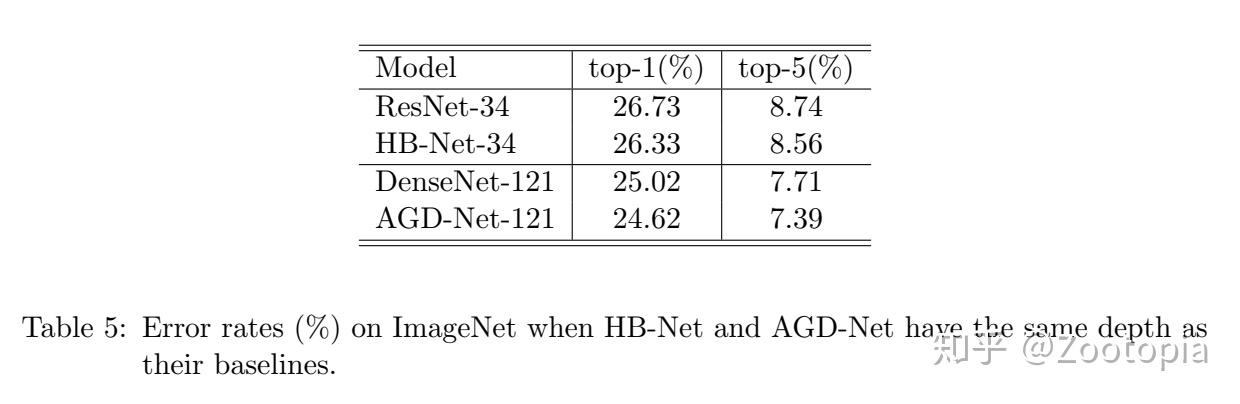
何凯明的ResNet论文中阐述过关于NN的深度问题,一般的网络在18层就很难收敛了需要一个warming-up,那么这个论文在ResNet(18)时候是通过重复实验从而得到收敛结果的,但是HB-Net是需要一次实验即可得到收敛结果,所以HB-Net可能在解决网络深度困境上表现更优秀。
【个人感想】这个论文作者一直在强调是一个初步的结果,但是这个初步探索给了大家一个新的视野去看待DNN,同样也给了做CS或者稀疏优化等一个新的视野去解决一些问题,尝试建立不同领域的联系,真的很interesting!




